

Thanks to the Task Asynchronous Programming model writing asynchronous code in .NET is usually straightforward. Apart from Tasks, the .NET platform comes with a variety of different features that the developers in writing safe code, such as the Task Parallel Library or concurrent data structures. One such feature that rarely gets its spot in the limelight is Channels.
Channels are probably most familiar to people who've dabbled in Go since they are often used for communication between goroutines. But if you are a C# person and want to learn what the fuss is about, I encourage you to read these two posts from Jeremy Clark:
 Jeremy
Jeremy Jeremy
JeremyIf you've got the basics down, the rest of the post should be a breeze. Let's start with a theoretical scenario. Imagine you have a web application that periodically receives data from a set of devices at frequent intervals. The data then must be analyzed, and the result of the analysis should be persisted in some kind of storage. Because the analysis can take a long time, it has to be done in the background so as not to make the devices wait for their results.
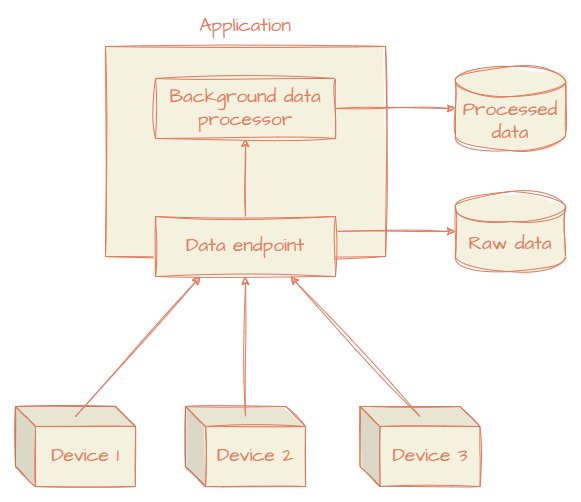
The data from each device is independent and therefore can be processed in parallel to increase the efficiency of your application.
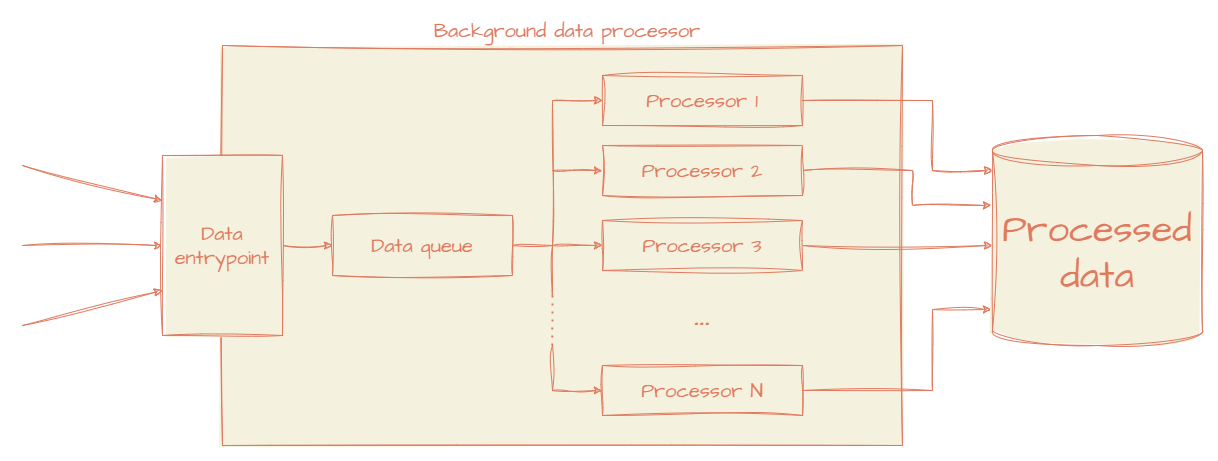
And that's what we will be building today!
Let's start with a simple wrapper for the data that also contains a Key property, which is used for "grouping" the data. Two DataWithKey instances with the same Key cannot be processed in parallel. With the scenario above in mind, the Key would indicate the device identifier. The IDataProcessor interface will be used to schedule the data for processing in the background.
public record DataWithKey(Guid Key, string Data);
public interface IDataProcessor
{
Task ScheduleDataProcessing(DataWithKey data);
}Because the data processor should be available throughout the whole lifetime of the application, we can use the BackgroundService base class and register it as a hosted service.
public class BackgroundDataProcessor : BackgroundService, IDataProcessor
{
private readonly Channel<DataWithKey> _internalQueue = Channel.CreateUnbounded<Data>(new UnboundedChannelOptions { SingleReader = true });
protected override Task ExecuteAsync(CancellationToken stoppingToken)
{
// TODO: Process data from _internalQueue
return Task.CompletedTask;
}
public async Task ScheduleDataProcessing(DataWithKey data) => await _internalQueue.Writer.WriteAsync(data);
}The _internalQueue Channel will be where the DataWithKey instances from the IDataProcessor users will be waiting for assignment to a key-specific processor. Because the only reader of that Channel will be the BackgroundDataProcessor instance, the SingleReader option is used to help guide the runtime towards some optimizations. Let's update the ExecuteAsync method:
protected override async Task ExecuteAsync(CancellationToken stoppingToken)
{
await foreach (var data in _internalQueue.Reader.ReadAllAsync(stoppingToken))
{
// TODO: Get or create processor task
// TODO: Schedule data processing for that processor
}
}To keep track of the key-specific data processors, let's use a Dictionary - since the BackgroundDataProcessor will be a Singleton, there's no need to use the concurrent variant. Taking care of the first TODO is easy:
public class BackgroundDataProcessor : BackgroundService, IDataProcessor
{
...
private readonly Dictionary<Guid, KeySpecificDataProcessor> _dataProcessors = new();
...
protected override async Task ExecuteAsync(CancellationToken stoppingToken)
{
await foreach (var data in _internalQueue.Reader.ReadAllAsync(stoppingToken))
{
var processor = GetOrCreateDataProcessor(data.Key);
// TODO: Schedule data processing for that processor
}
}
private KeySpecificDataProcessor GetOrCreateDataProcessor(Guid key)
{
if (!_dataProcessors.ContainsKey(key))
{
_dataProcessors[key] = new KeySpecificDataProcessor(key);
}
return _dataProcessors[key];
}
...
}
public class KeySpecificDataProcessor
{
public Guid ProcessorKey { get; }
public KeySpecificDataProcessor(Guid processorKey)
{
ProcessorKey = processorKey;
}
}But the second one will take a bit more work. Let's first prepare the KeySpecificDataProcessor. It will also have a queue Channel but also a Task that will be taking items from the queue and doing the actual processing.
public class KeySpecificDataProcessor : IDataProcessor
{
public Guid ProcessorKey { get; }
private Task? _processingTask;
private readonly Channel<DataWithKey> _internalQueue = Channel.CreateUnbounded<Data>(new UnboundedChannelOptions { SingleReader = true, SingleWriter = true });
private KeySpecificDataProcessor(Guid processorKey)
{
ProcessorKey = processorKey;
}
private void StartProcessing(CancellationToken cancellationToken = default)
{
_processingTask = Task.Factory.StartNew(
async () =>
{
await foreach (var data in _internalQueue.Reader.ReadAllAsync(cancellationToken))
{
// TODO: Process data
}
}, cancellationToken, TaskCreationOptions.LongRunning, TaskScheduler.Default);
}
public async Task ScheduleDataProcessing(DataWithKey data)
{
if (data.Key != ProcessorKey)
{
throw new InvalidOperationException($"Data with key {data.Key} scheduled for KeySpecificDataProcessor with key {ProcessorKey}");
}
await _internalQueue.Writer.WriteAsync(data);
}
public static KeySpecificDataProcessor CreateAndStartProcessing(Guid processorKey, CancellationToken processingCancellationToken = default)
{
var instance = new KeySpecificDataProcessor(processorKey);
instance.StartProcessing(processingCancellationToken);
return instance;
}
}Since we know that only the BackgroundDataProcessor (a singleton) will be calling the ScheduleData method and the internal Task will be the only reader, the KeySpecificDataProcessor._internalQueue features both SingleReader and SingleWriter options enabled. The constructor is replaced with a factory method so that the class cannot be created without starting the processing Task. Now it's only a matter of updating the BackgroundDataProcessor to use the CreateAndStartProcessing method instead of calling the constructor and removing the remaining TODO:
public class BackgroundDataProcessor : BackgroundService, IDataProcessor
{
...
protected override async Task ExecuteAsync(CancellationToken stoppingToken)
{
await foreach (var data in _internalQueue.Reader.ReadAllAsync(stoppingToken))
{
var processor = GetOrCreateDataProcessor(data.Key);
processor.ScheduleDataProcessing(data)
}
}
private KeySpecificDataProcessor GetOrCreateDataProcessor(Guid key, CancellationToken processorCancellationToken = default)
{
if (!_dataProcessors.ContainsKey(key))
{
_dataProcessors[key] = KeySpecificDataProcessor.CreateAndStartProcessing(key, processorCancellationToken);
}
return _dataProcessors[key];
}
...
}And it's done - sans the actual processing magic, but that's not the point here. I know you'll look at the code and be like: "yeah, you used Channels, but there does not seem to be much benefit to them compared to say, a BlockingCollection backed by a ConcurrentQueue". And I agree with you - apart from the SignleWriter/SingleReader optimizations, there's not much benefit yet.
Let's go to the original scenario and see what could be improved. One thing that's possible is device malfunction or shutdown. If that happens, no more data from that device will be pushed to the endpoint. In that case, all the resources related to the processor of that device are just laying there, wasting resources.
To fix that, we need three things:
- A timestamp associated with each of the
KeySpecificDataProcessors pointing to the time when they finished processing data, - A mechanism to stop the processing task,
- Something that will monitor the current
KeySpecificDataProcessorset and clean up the ones which finished processing some time ago.
The second point is the easiest one, so this is where we'll start. This is where we'll be able to use one of the cool features of Channels - marking them as complete - meaning that no more data will be written. Once the channel is empty, the ChannelReader.ReadAllAsync method will finish the enumeration, and the processing task will finish. The following method will do just that:
public class KeySpecificDataProcessor : IDataProcessor
{
...
public async Task StopProcessing()
{
_internalQueue.Writer.Complete();
if (_processingTask != null)
{
await _processingTask;
}
}
...
}Now let's tackle the timestamp point. When I first created a proof-of-concept for this post, I simply stored a timestamp alongside the KeySpecificDataProcessor reference in BackgroundDataProcessor, which was updated every time something was queued for it. When I got to it now, something didn't sit right with me.
If the processing takes a long time, then there might be a long queue of data items waiting to be processed. If the data stops coming, the processor might get marked as "expired" because no data has been scheduled for it for some time. But it might still be processing data from the Channel. If that happens, the await in the StopProcessing method will take a while to complete because the Task will not complete until everything in the Channel has been processed.
That's why this time, the KeySpecificDataProcessor will hold its own timestamp because only the processor knows the state of the processing at any given moment.
public class KeySpecificDataProcessor : IDataProcessor
{
...
public DateTime LastProcessingTimestamp => _processingFinishedTimestamp ?? DateTime.UtcNow;
private DateTime? _processingFinishedTimestamp = DateTime.UtcNow;
private bool Processing
{
set
{
if (!value)
{
_processingFinishedTimestamp = DateTime.UtcNow;
}
else
{
_processingFinishedTimestamp = null;
}
}
}
...
private void StartProcessing(CancellationToken cancellationToken = default)
{
_processingTask = Task.Factory.StartNew(
async () =>
{
await foreach (var data in _internalQueue.Reader.ReadAllAsync(cancellationToken))
{
Processing = true;
await ProcessData(data);
Processing = _internalQueue.Reader.TryPeek(out _);
}
}, cancellationToken, TaskCreationOptions.LongRunning, TaskScheduler.Default);
}
private async Task ProcessData(DataWithKey data)
{
// TODO: Process data
await _dependency.DoStuff();
}
public async Task ScheduleDataProcessing(DataWithKey dataWithKey)
{
if (dataWithKey.Key != ProcessorKey)
{
throw new InvalidOperationException($"Data with key {dataWithKey.Key} scheduled for KeySpecificDataProcessor with key {ProcessorKey}");
}
Processing = true;
await _internalQueue.Writer.WriteAsync(dataWithKey);
}
...
}The Channel.TryPeek method will tell us whether there are more data items waiting to be processed and if there are - the LastProcessingTimestamp property will keep returning the current timestamp so that the processor is not cleaned up.
For the actual monitoring, let's create a separate class that will spawn its own Task to periodically check the processors and stop them if necessary.
public partial class BackgroundDataProcessor
{
public class BackgroundDataProcessorMonitor
{
private readonly TimeSpan _processorExpiryThreshold = TimeSpan.FromSeconds(30);
private readonly TimeSpan _processorExpiryScanningPeriod = TimeSpan.FromSeconds(5);
private MonitoringTask? _monitoringTask;
private readonly SemaphoreSlim _processorsLock;
private readonly Dictionary<Guid, KeySpecificDataProcessor> _dataProcessors;
private BackgroundDataProcessorMonitor(SemaphoreSlim processorsLock, Dictionary<Guid, KeySpecificDataProcessor> dataProcessors)
{
_processorsLock = processorsLock;
_dataProcessors = dataProcessors;
}
private void StartMonitoring(CancellationToken cancellationToken = default)
{
var tokenSource = CancellationTokenSource.CreateLinkedTokenSource(cancellationToken);
var task = Task.Factory.StartNew(async () =>
{
using var timer = new PeriodicTimer(_processorExpiryScanningPeriod);
while (!tokenSource.IsCancellationRequested && await timer.WaitForNextTickAsync(tokenSource.Token))
{
if (!await _processorsLock.WaitWithCancellation(tokenSource.Token))
{
continue;
}
var expiredProcessors = _dataProcessors.Values.Where(IsExpired).ToArray();
foreach (var expiredProcessor in expiredProcessors)
{
await expiredProcessor..StopProcessing();
_dataProcessors.Remove(expiredProcessor.ProcessorKey);
}
_processorsLock.Release();
}
}, tokenSource.Token, TaskCreationOptions.LongRunning, TaskScheduler.Default);
_monitoringTask = new MonitoringTask(task, tokenSource);
}
private bool IsExpired(KeySpecificDataProcessor processor) => (DateTime.UtcNow - processor.LastProcessingTimestamp) > _processorExpiryThreshold;
public async Task StopMonitoring()
{
if (_monitoringTask.HasValue)
{
if (!_monitoringTask.Value.CancellationTokenSource.IsCancellationRequested)
{
_monitoringTask.Value.CancellationTokenSource.Cancel();
}
await _monitoringTask.Value.Task;
_monitoringTask.Value.CancellationTokenSource.Dispose();
_monitoringTask = null;
}
}
public static BackgroundDataProcessorMonitor CreateAndStartMonitoring(SemaphoreSlim processorsLock, Dictionary<Guid, KeySpecificDataProcessor> dataProcessors, CancellationToken monitoringCancellationToken = default)
{
var monitor = new BackgroundDataProcessorMonitor(processorsLock, dataProcessors);
monitor.StartMonitoring(monitoringCancellationToken);
return monitor;
}
private readonly record struct MonitoringTask(Task Task, CancellationTokenSource CancellationTokenSource);
}
}
public static class SemaphoreSlimExtensions
{
public static async Task<bool> WaitWithCancellation(this SemaphoreSlim semaphore, CancellationToken cancellationToken)
{
try
{
await semaphore.WaitAsync(cancellationToken);
}
catch (OperationCanceledException)
{
return false;
}
return true;
}
}This might look like a lot of code again, but all it really does is spawn a separate Task that uses the PeriodicTimer to check if any KeySpecificDataProcessor's LastProcessingTimestamp is further back than the specified expiry threshold. If it is, it then calls the StopProcessing method and removes it from the Dictionary holding the active processors.
Now we have all the things we needed for cleaning up unused resources. The only thing that's left now is using it in the BackgroundDataProcessor:
public partial class BackgroundDataProcessor : BackgroundService, IDataProcessor
{
...
private readonly SemaphoreSlim _processorsLock = new(1, 1);
private BackgroundDataProcessorMonitor? _monitor;
protected override async Task ExecuteAsync(CancellationToken stoppingToken)
{
_monitor = BackgroundDataProcessorMonitor.CreateAndStartMonitoring(_processorsLock, _dataProcessors, _loggerFactory.CreateLogger<BackgroundDataProcessorMonitor>(), stoppingToken);
await foreach (var data in _internalQueue.Reader.ReadAllAsync(stoppingToken))
{
if (!await _processorsLock.WaitWithCancellation(stoppingToken))
{
break;
}
var processor = GetOrCreateDataProcessor(data.Key, stoppingToken);
await processor.ScheduleDataProcessing(data);
_processorsLock.Release();
}
await _monitor.StopMonitoring();
}
private KeySpecificDataProcessor GetOrCreateDataProcessor(Guid key, CancellationToken newProcessorCancellationToken = default)
{
if (!_dataProcessors.TryGetValue(key, out var deviceProcessor))
{
var processor = CreateNewProcessor(key, newProcessorCancellationToken);
_dataProcessors[key] = processor;
deviceProcessor = processor;
}
return deviceProcessor.Processor;
}
...
}Alright, this should do it - no more wasting resources. This has become a really long post, and if you're here (thank you!) you're probably thinking we should be done by now. Just one more thing, I promise.
So if you take a look at the method doing the actual processing - KeySpecificDataProcessor.ProcessData you will see that it does nothing. That's because it's difficult to do anything without some dependencies. You could just new all of the things you need, but don't do that.
Imagine the following dependency:
public interface IDependency
{
Task DoStuff();
}Let's extend the KeySpecificDataProcessor with a mechanism for resolving it from a DI container.
public class KeySpecificDataProcessor : IDataProcessor
{
...
private readonly IServiceScopeFactory _serviceScopeFactory;
private KeySpecificDataProcessor(Guid processorKey, IServiceScopeFactory serviceScopeFactory)
{
ProcessorKey = processorKey;
_serviceScopeFactory = serviceScopeFactory;
}
private void StartProcessing(CancellationToken cancellationToken = default)
{
_processingTask = Task.Factory.StartNew(
async () =>
{
await foreach (var data in _internalQueue.Reader.ReadAllAsync(cancellationToken))
{
Processing = true;
using (var dependenciesProvider = new DependenciesProvider(_serviceScopeFactory))
{
await ProcessData(data, dependenciesProvider.Dependency);
}
Processing = _internalQueue.Reader.TryPeek(out _);
}
}, cancellationToken, TaskCreationOptions.LongRunning, TaskScheduler.Default);
}
private async Task ProcessData(DataWithKey data, IDependency dependency)
{
await dependency.DoStuff();
}
...
public static KeySpecificDataProcessor CreateAndStartProcessing(Guid processorKey, IServiceScopeFactory serviceScopeFactory, CancellationToken processingCancellationToken = default)
{
var instance = new KeySpecificDataProcessor(processorKey, serviceScopeFactory);
instance.StartProcessing(processingCancellationToken);
return instance;
}
private class DependenciesProvider : IDisposable
{
private readonly IServiceScope _scope;
public IDependency Dependency { get; }
public DependenciesProvider(IServiceScopeFactory serviceScopeFactory)
{
_scope = serviceScopeFactory.CreateScope();
Dependency = _scope.ServiceProvider.GetRequiredService<IDependency>();
}
public void Dispose()
{
_scope.Dispose();
}
}
}Here we create a new scope every time a new data item is processed because that feels like the most natural scope, but that can, of course, easily be changed to a scope-per-KeySpecificDataProcessor if that suits your needs better.
Now it's time to update the BackgroundDataProcessor to get the IServiceScopeFactory via constructor injection and pass it down to the KeySpecificDataProcessor instances.
public partial class BackgroundDataProcessor : BackgroundService, IDataProcessor
{
...
private readonly IServiceScopeFactory _serviceScopeFactory;
...
public BackgroundDataProcessor(IServiceScopeFactory serviceScopeFactory)
{
_serviceScopeFactory = serviceScopeFactory;
}
...
private KeySpecificDataProcessor CreateNewProcessor(int dataKey, CancellationToken processorCancellationToken = default)
{
return KeySpecificDataProcessor.CreateAndStartProcessing(dataKey, _serviceScopeFactory, processorCancellationToken);
}
...
}And we're done! 🥳
Of course, there are more things that could be done to improve the processor - this is just the foundation. There's error handling, queue data retention, testing, and more fine-grained locking mechanisms to add to really make the processing resilient and reliable. And not to mention tweaking it to best suit your needs - I opted to use Tasks with the LongRunning option, but maybe Threads would be better or short-lived Tasks. The monitoring intervals also need to be empirically adjusted. But I will leave that up to you - this has already grown more than I had imagined!
Of course, this might end up being a very complex part of your system. As always, you should take a look at the alternatives, such as the TPL Dataflow library and decide what will be best for your system and your team in terms of understandability and maintainability.
The whole source code packaged together with a simple console application to see it running can be found at:
 mzwierzchlewski
mzwierzchlewskiIf the topic piqued your interest, there are some links I wanted to share.
First, if you are wondering about doing a similar thing, but using a ConcurrentQueue, have a look at xUnit's implementation of a SynchronizationContext:
xunitThen, if you found Channels similar to Observables known from reactive libraries, this library provides some interesting capabilities, such as batching, filtering and transforming:
Open-NET-LibrariesAnd last but not least, apart from the posts about Channels linked at the beginning of the posts, this series from Denis Kyashif is also top-notch:

Cover photo by Ingrid Martinussen on Unsplash